


Привет, на связи команда агентства KINETICA. Мы предлагаем бизнесам полный спектр услуг: от SEO и контекстной рекламы до email-маркетинга и управления репутацией.
В этом кейсе расскажем, как нам удалось ускорить процесс SEO-проектирования архитектуры для маркетплейса до 2100+ категорий.
Небольшой спойлер: это стало возможным с помощью парсинга семантики конкурента по маскам URL в Keys.so и автоматизации процессов с ИИ.
 Содержание
Содержание- Клиент и задача
- Этап 1. Сбор семантики с Keys.so: 700 000 запросов
- Что даёт Keys.so на этом этапе — и чего не дают альтернативы
- Этап 2. Дистилляция: от 700 000 к 15 000 рабочих фраз
- Фильтрация скриптами: четыре критерия отсева
- Этап 3. Архитектура: как добыть структуру у конкурентов, которые закрыты от парсинга
- Metadata Extraction: «низкотехнологичный» метод с высоким КПД
- N8N как клей: мультикатегорийность без ошибок
- Этап 4. Промышленная генерация мета-тегов: AI-контролер качества
- Этап 5. Визуализация: 2200 категорий в XMind без потери данных
- Результаты
Клиент и задача
К нам обратилась федеральная сеть магазинов авторских товаров, винтажа и предметов коллекционирования — 48 филиалов в 34 городах России.
Задача: трансформация сайта-«визитки» в полноценный маркетплейс, способный конкурировать в поисковой выдаче с «Ярмаркой Мастеров» и Avito.
Цель — спроектировать SEO-архитектуру каталога на основе реального поискового спроса: логичная иерархия URL, система автоматической генерации метаданных для десятков тысяч будущих страниц.
Две фундаментальные сложности сразу обозначили масштаб проблемы.
Во-первых, ниша — одна из самых раздробленных на рынке: есть «Ярмарка Мастеров» и Avito, есть мелкие лавки, и нет ни одного эталона, который объединял бы антиквариат, зоотовары, фермерские продукты и материалы для творчества в одну логичную структуру.
Во-вторых, скрытый масштаб: мы ещё не знали, что «стандартная задача» вырастет до 2100+ категорий и потребует собственного софта.
Этап 1. Сбор семантики с Keys.so: 700 000 запросов
Первый шаг — получить полную семантику рынка. Мы начали с выгрузки данных по крупнейшему конкуренту через Keys.so.
Стандартный подход — анализ всего домена сразу, здесь не работал: маркетплейс такого масштаба генерирует настолько широкую семантику, что единая выгрузка либо упирается в лимиты, либо возвращает «смешанный» массив без структуры, который сложно сегментировать.
Наше решение — парсинг «кусочками» по маскам URL.
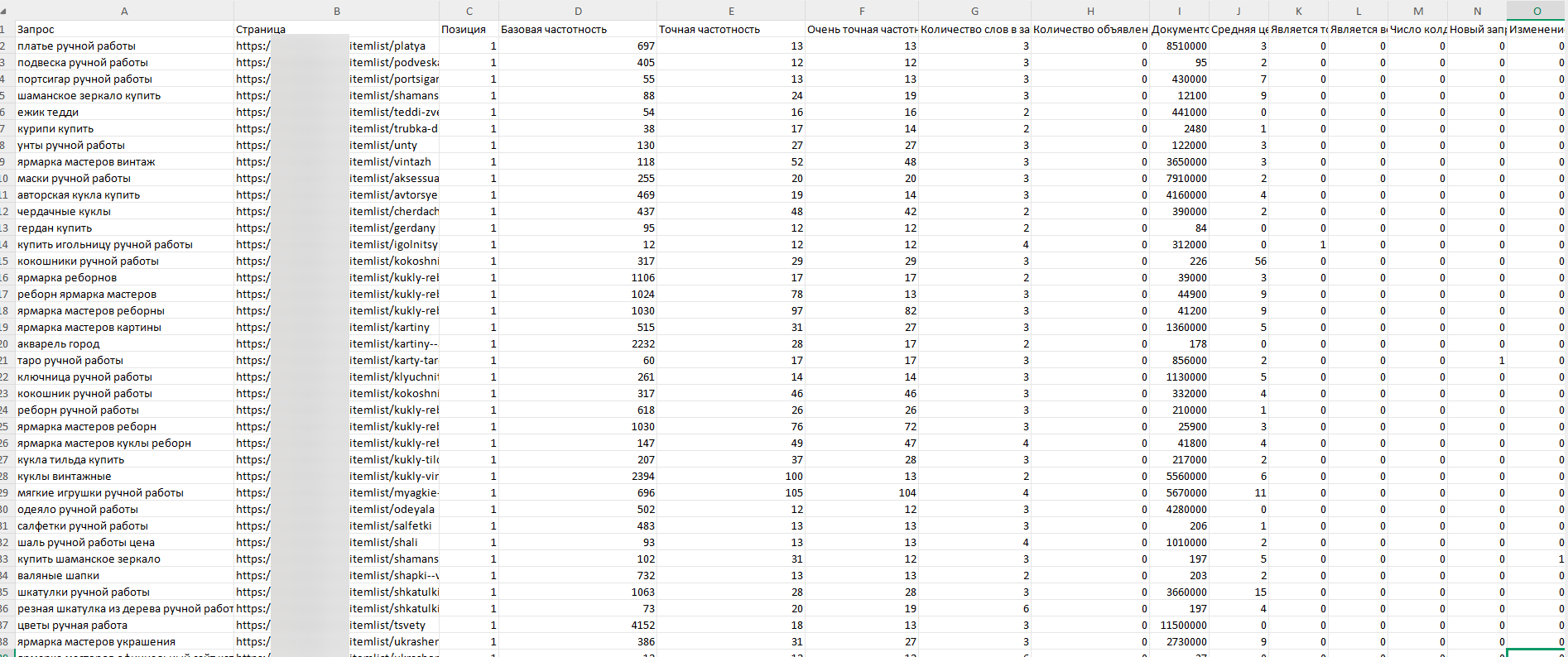
В интерфейсе Keys.so, в разделе анализа домена «Запросы сайта в органической выдаче», мы использовали фильтрацию по URL-маске. Последовательно вытаскивали семантику по отдельным разделам сайта конкурента:
- /itemlist/ — листинги товарных категорий
- /tag/ — тегированные подборки
- /popular/ — страницы популярных товаров

Каждый срез выгружали отдельно в Excel, затем объединяли. Такой подход позволил обойти ограничения на объём одной выгрузки и сразу получить семантику с привязкой к структурным разделам сайта — это критически важно для следующего этапа.
Итог: файл на 700 000 запросов с колонками: фраза, URL страницы конкурента, позиция, несколько видов частотности, количество объявлений.
Что даёт Keys.so на этом этапе — и чего не дают альтернативы
Стандартный путь в такой задаче — Яндекс.Вордстат плюс KeyCollector.
Проблема: Вордстат даёт спрос по отдельным запросам, но не показывает, под какие именно URL-ы конкурент уже собирает трафик. Вы строите структуру вслепую, угадывая, какие категории нужны рынку.
Keys.so решает это иначе: выгрузка по домену конкурента сразу даёт связку «запрос — URL посадочной страницы». Это означает, что вы видите не просто список ключей, а логику, которую рынок уже одобрил — реальные категории с реальным трафиком.
На маркетплейсе с тысячами SKU это разница между неделями гипотез и готовым скелетом за один день.
Этап 2. Дистилляция: от 700 000 к 15 000 рабочих фраз
700 000 запросов — не ядро, а шум с вкраплениями ценных данных. Прогонять весь массив через ИИ или KeyCollector на этом этапе — значит потратить бюджет впустую и получить результат через несколько недель.
Фильтрация скриптами: четыре критерия отсева
Мы написали кастомные скрипты на Google Apps Script, которые прогнали массив через четыре фильтра:
- Частотность: убрали всё с показами ниже 12-20 раз в год.
- Длина фразы: удалили запросы длиннее 6 слов — они, как правило, несут нецелевой информационный шум.
- Позиция конкурента: если фраза у конкурента ниже 30-й строчки — вероятно, смешанный интент, в корзину.
- CPC как маркер коммерциализации: фразы с высокой стоимостью клика помечали как приоритетные — за ними стоит реальный покупательский спрос.
Крупный конкурент — это сотни брендов конкурентов в семантике. Вычищать их вручную — адский труд.
Мы применили другой подход: сканировали главную страницу каждого конкурента и просили ИИ сформировать полный список минус-слов по бренду.
Нейросеть справляется с десятками брендов за пару минут, где раньше уходили часы. В итоге с 700 000 фраз мы спустились до 15 000 чистых, коммерчески валидных запросов.

Этап 3. Архитектура: как добыть структуру у конкурентов, которые закрыты от парсинга
Следующий барьер — логика вложенности категорий. Screaming Frog и sitemap.xml не дали ничего: конкуренты в нише хорошо защищены от автоматического сбора.
Вы читаете блог Keys.so, сервиса анализа сайтов в SEO и контекстной рекламе

Metadata Extraction: «низкотехнологичный» метод с высоким КПД
Решение оказалось неочевидным. Мы вручную скопировали списки категорий из каталогов конкурентов в Google Таблицы.
При таком копировании таблицы автоматически подтягивают гиперссылки, зашитые в заголовки. Дальше — простой Google Apps Script, который за секунды извлёк все URL из названий категорий в отдельную колонку.
Зачем нам были нужны именно URL? Семантика из Keys.so уже содержала привязку «запрос — URL конкурента». Получив структуру адресов с самого сайта, мы мгновенно «сшили» ключевые фразы с конкретными разделами каталога — без ручной разметки, без гипотез.
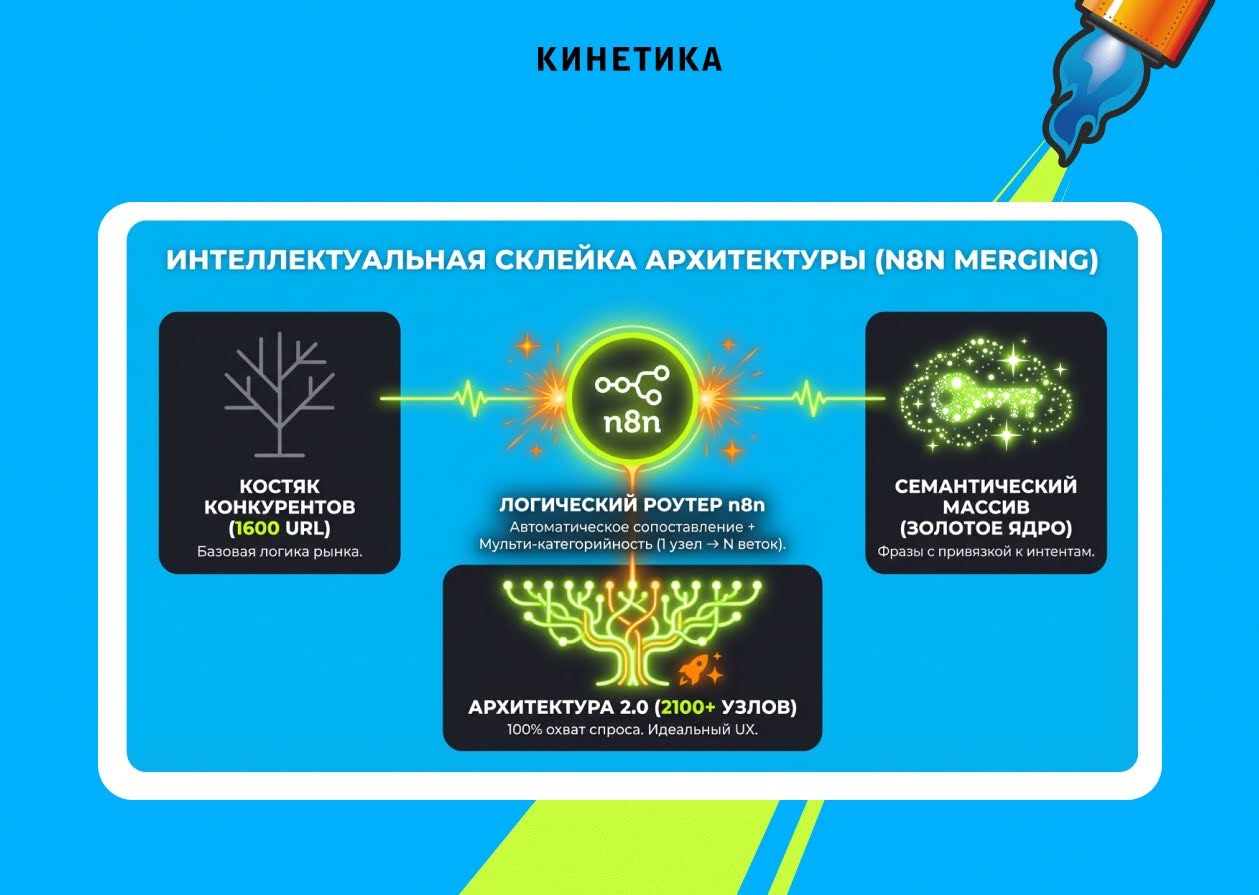
Это и есть главный практический приём этого этапа: Keys.so даёт вам семантику с привязкой к URL — вам остаётся только извлечь структуру URL с самого сайта и соединить два источника. Костяк из ~1600 категорий с целевыми фразами собирается быстро.
N8N как клей: мультикатегорийность без ошибок
Анализ показал: семантика конкурентов местами выходила за рамки 1600 категорий. Чтобы закрыть весь спрос, мы добавляли категории из нашего первичного массива — и здесь одна и та же подкатегория могла попасть сразу в несколько родительских веток (осознанное решение ради удобства пользователей).
Такую склейку вручную — с учётом мультикатегорийности и тысяч пересечений — не сделать без ошибок. Мы передали её цепочке в n8n.
Итог: структура доросла до 2100+ узлов.
Этап 4. Промышленная генерация мета-тегов: AI-контролер качества
2100 категорий — это 2100 Title и Description, которые нужно написать. Просто «нагенерить» их через ChatGPT — значит получить гору ошибок в склонениях, выходы за лимиты символов и галлюцинации.
Мы собрали цепочку в n8n по принципу «доверяй, но проверяй»:
- Триггер: нода забирает данные из таблицы (категория + целевые фразы из Keys.so).
- Scraping (извлечение данных): модуль обращается к живой странице конкурента, чтобы понять контекст товаров.
- Generation (генерация): модель OpenAI создаёт варианты Title и Description по нашим шаблонам.
- Validation (узел «Оценщик», проверка): вторая модель ИИ выступает цензором — проверяет склонения (мы использовали родительный падеж «Выбор [чего?]»), соответствие лимитам символов, отсутствие галлюцинаций.
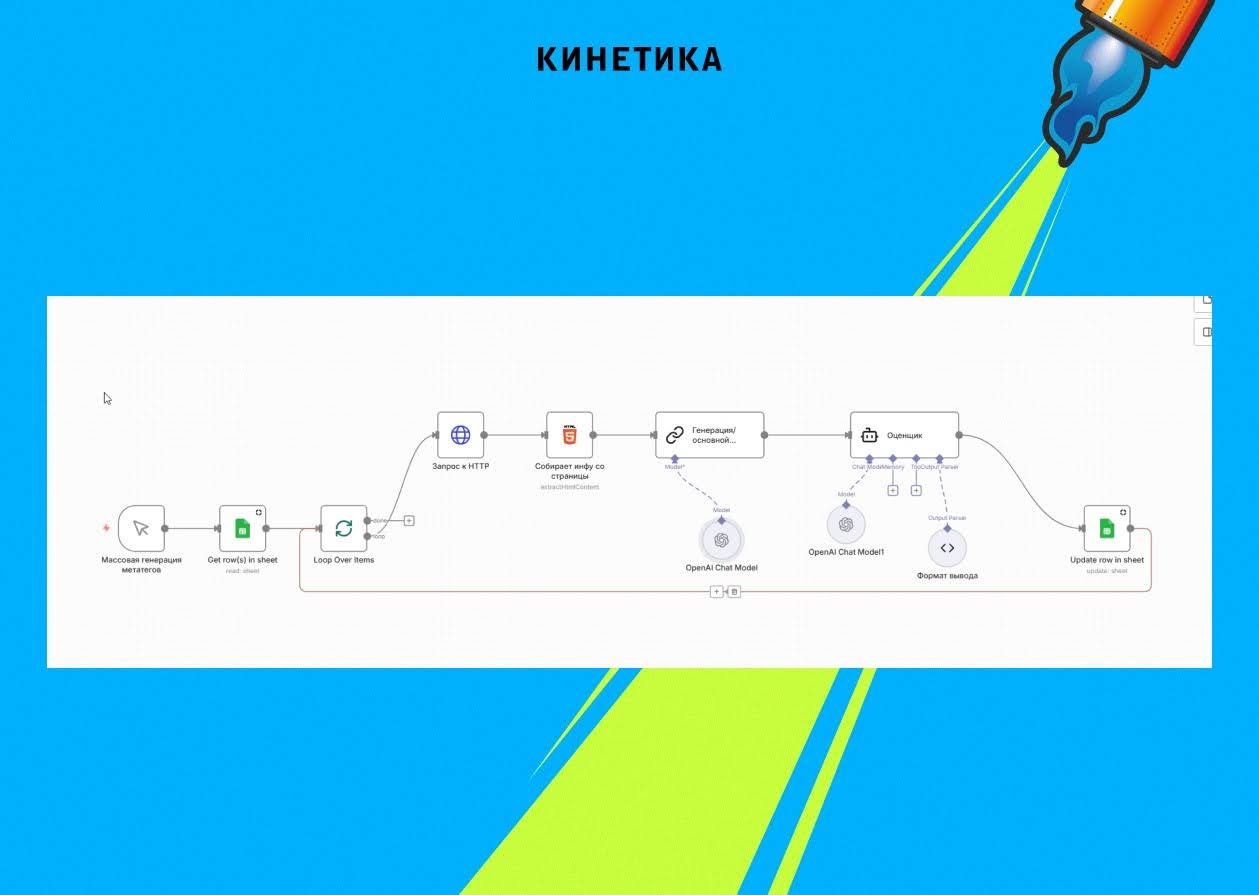
Специалист занимался стратегическими задачами, пока система генерировала и проверяла мета-теги в промышленном режиме.
Этап 5. Визуализация: 2200 категорий в XMind без потери данных
Финальный барьер — как показать клиенту структуру такого масштаба.
Таблица на тысячи строк — это запутать всех. Нужна была Mind-карта. Но XMind имеет лимит в 30 000 символов при импорте через буфер обмена, а наша структура пробивала его в несколько раз.
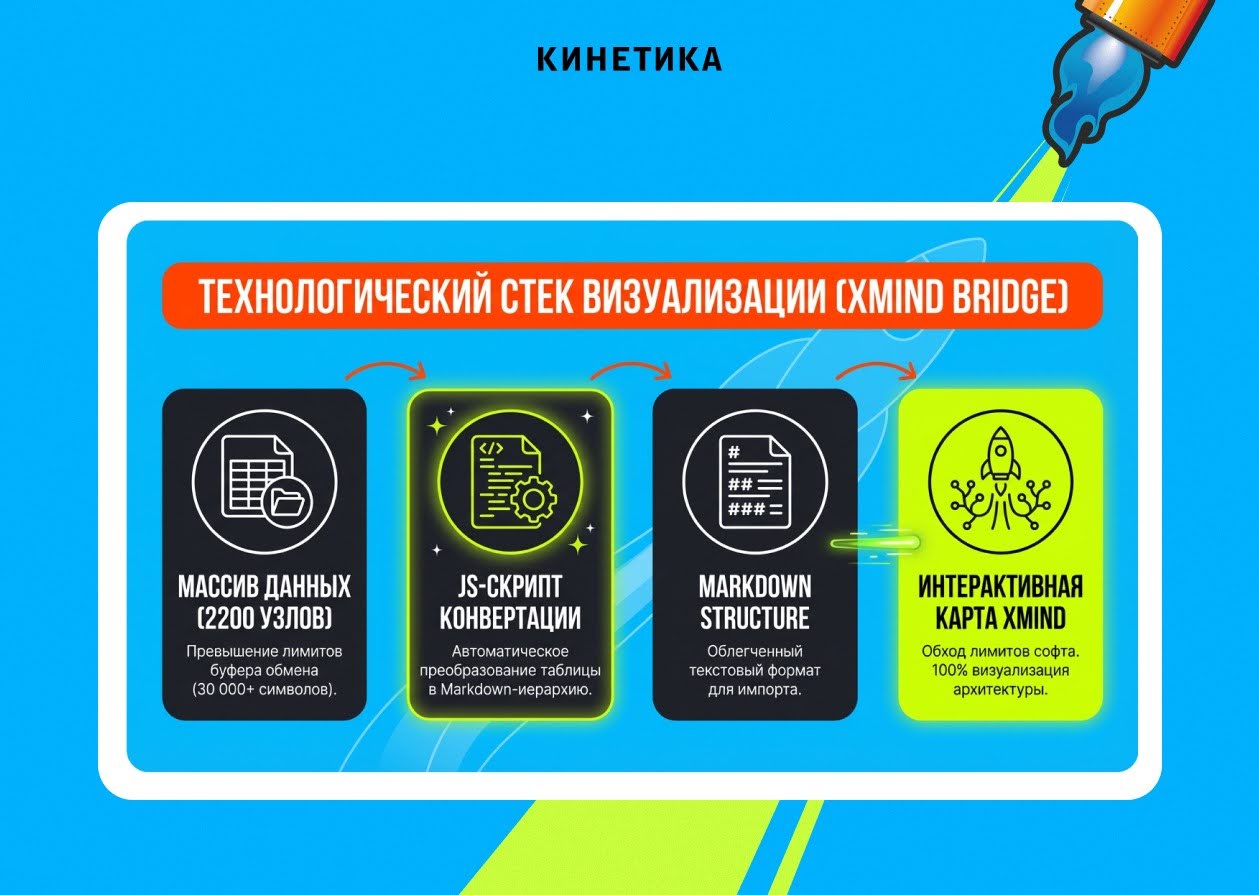
Решение — перевести всю структуру в Markdown.
Мы написали Google Apps Script, который преобразовал таблицу в древовидный Markdown-текст с системой решёток и отступов. XMind «проглотил» его мгновенно. За считанные секунды — наглядная карта всего проекта.
Результаты
| Показатель | Результат |
| Исходный массив | 700 000 запросов |
| Очищенное ядро | ~15 000 фраз |
| Итоговых категорий | 2100+ |
| Срок проектирования архитектуры | 5 дней |
До активного использования скриптов и ИИ сбор такого ядра — 15 000 чистых фраз и 2100 категорий — занимал месяцы работы SEO-отдела с высоким риском человеческих ошибок. Автоматизация сократила этот срок до 5 дней.
Ключевой инструмент на старте — Keys.so. Именно возможность парсить семантику конкурента по маскам URL позволила получить структурированный массив, а не бесформенную «кашу» из 700 000 запросов. Без привязки «запрос — URL» последующая сшивка семантики со структурой каталога была бы невозможна.
Добавим, что если вам интересно узнать больше о применении сервиса Keys.so, читайте кейсы в этом блоге. О том, как увеличить органический трафик интернет-магазина на 250% за 8 месяцев, смотрите в этой статье.













